In many cases there is a natural distance between objects, or we can readily define one, as shown for treemaps, fractal maps, and dendrograms. But a community is defined by communications. If two people never communicate, they can't be considered in the same community. We could define the distance between people as a simple function of the number of times M that they communicate (for example, distance = 1/M, so that frequent communicators are "closer"), and this is exactly what's done in the dendrogram, treemap, and fractal map demos.
For very clearcut data this is sufficient, but there are better measures (better = more closely agrees with more people's sense of community), as reviewed by Newman and Fortunato. My choice, implemented in Javascript in the source of this page, is the fast algorithm of Newman as accelerated by Clauset et al (= "CNM") and with weighting applied. I prefer it for several reasons:
The member-vs-not-member criterion is based on counting edges between nodes and between nascent communities, simple and intuitive. No need to hope that people are like resistor networks, for example.
It doesn't depend on fudge functions or parameters (How many eigenvectors to use? Should we take the log of the distance values? and so forth)
It's robust and works well with sparse data. (Between n nodes there could be n(n-1)/2 edges. Sparse datasets have many fewer than this, typically 5-20%).
It's exceptionally fast and scales very well.
The end result is a tree structure which has subsequent benefits in efficient access and display.
The results "make sense" with familiar data, judge for yourself.
Explore below results across a variety of datasets. The communities are the connected sets of nodes in the diagram, in the colored arcs. Note how cleanly the Munchkins, Kansas farmers, and Dorothy's chums are separated, and similarly how well the Montagues are separated from the Capulets and the minor characters.
From my admittedly pragmatic and informal point of view, that seems like a lot of extra work and complexity. The "most kosher" methods are more problematic to implement, and Berry et al want a complex bit of graph theory as preprocessor (with its own arbitrary stopping rule). Also Berry's approach gets in the way of using the original edge weight data we may have -- and we know that's really important to get the right result. Isn't there a way to rescue CNM -- to use it to find fine-structure too?
My solution is to apply the CNM method recursively. That's mentioned in the literature but not (as far as I know) implemented. Professor Newman very kindly answered my question about this, noting that "if it works for you, OK" but that recursion is an iffy approach: because "the modularity of a network is not the sum of the modularities," recursive application of CNM is not going to optimize the overall modularity. Fair enough: I completely defer to Newman on theory and experience. And yet let's explore this point philosophically (if not mathematically):
First, how is recursion implemented? Quite simply, I take any given community, ignore all nodes outside of it, and also ignore all edges from the inside nodes to other nodes that are now outside. Then this entirely new sub-graph is dropped into the CNM algorithm, and the process is continued (in a depth-first tree sequence) until ΔQ goes negative (on the way down) or until tiny modules are reached (at the bottom). Most of these tiny graphs bottom out as binaries (two nodes, one edge) or isolated nodes which are simple endpoints. Interestingly there are several tiny graphs which throw errors in my implementation of CNM -- probably some degeneracy I haven't figured out fully, which I simply trap as another signal that we've bottomed out the recursion.
OK, modularity is not additive. But what if we change the goal slightly: we're not seeking an overall modularity optimization, but rather community structure determination. I couldn't begin to tell you how to calculate the overall Q value after the recursion is done! But what we might be able to say is that "from here on down (to the next √(L/2) limit)" we've got a really good identification of the communities." That's all we hope for with the recursive approach.
It's interesting to ponder whether it matters that we slice away the "higher level" edges when diving into recursion. Intuitively those links into various nodes inside our chunk should affect the communities we find (and this may be the crux of the issue). But step back: who's to say that our original big graph is sacrosanct? Our data are never complete, there must be links out to other nodes of which we are ignorant &mdash so like it or not we're pragmatists. So recursion does the best it can with the sub-community in isolation, just as the macro community exists in isolation. We maximize Q for each sub-level but probably not for the graph as a whole, which probably implies that our definition of community is changing with scale. Sounds radical — but who says community must be a scale-free property? It is, after all, constrained to integers and bounded by unity at the bottom.
The old physicist in me therefore wonders if we should slap some sort of "dielectric constant" on the space surrounding all our graphs, to smooth out the fact that there are always links to exterior nodes. This is what's done all the time in scaling problems when the complexity gets huge (for example with simulated annealing to optimize protein structure, because fudging the distant shells of water is better than vacuum). My other hunch is that recursion might be OK but only if its stopping rule is better thought out: I agree that communities of 1 to 3 nodes at the scale of the internet (millions to billions of nodes) feels wrong. So it's a Goldilocks problem: CNM finds too few communities, but exhaustive CNM recursion probably finds too many. But all this is for the better theorists to ponder...
Why challenge expert opinions? Simply because CNM is so efficient and compact that using it recursively is a very attractive way to see finer community structure in large networks. Very casual argument: the graphs in the demo below "look good" -- the subcommunities found by recursion match the link structure (gray arcs) and also match the storylines of the sources. The other philosophical reason is that I've always been an experimental scientist (biochemistry mostly), so I view input data as wonderful but not sacred: there are unknown sources of error or incompleteness in the inputs, so I don't get too fussed about approximations in the analysis (when done openly for a good reason). That dolphin nudge we didn't see, that karate coaching we missed, that arbitrary rule of what constitutes an interaction in Les Miserables, all contribute to fuzz around the edges. So I invite all feedback! And I'm really interested if you have an opinion on a justifiable stopping rule that makes recursive CNM more legitimate.
About the Ring Graph
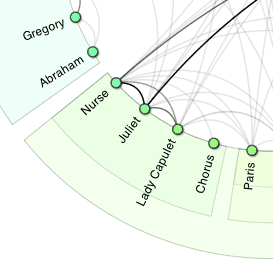
The "ring graph" below is very information-rich. The curved lines in the center show all of the interactions between characters, with intensity shown by the gray-to-black coloring ; thus in the snapshot to the right Juliet and Nurse have many more conversations (betweeen themselves and across to Romeo) than either Chorus or Abraham. Some of the datasets are unweighted and so all gray. Weighting makes an enormous positive difference in the grouping, so when it's available in the data I don't offer an unweighted analysis option.
The concentric color arcs show all of the communities and sub-communities as found by exhaustive recursive application of the Clauset-Newman-Moore method. So we see that Nurse-Juliet-LadyCapulet-Chorus are a sub-community within a larger greenish-yellow community that includes Paris some other characters. Gregory and Abraham are in an entirely different major community, in fact they have no direct interactions with the Nurse-Juliet group.
The ordering of characters around the ring is according to their communities and sub-communities, so we expect (and generally observe) more connections near the rim, i.e. within communities. Thus the ordering conveys information, minimizes line-crossing clutter, and opens up white space in the gaps between major communities.
This ring graph also has the advantage of being completely deterministic and built through an efficient tree structure. It's more common to see social networks displayed with iterative force-directed algorithms, but in my experiments I find them visually messy, far too slow to create, and worrisome in the number of parameters needed to get a good result. For example, compare Figures 2a and 2c in the Fortunato paper to the karate club and dolphins displays of the same datasets below. With the ring graph I can follow connections without getting lost in the spaghetti, see hierarchies of communities (never possible in a force-graph), and quickly spot the high-connectors by the fountain-like density of their links (look for "old" and "little" in the David Copperfield word pairs data).
 The "ring graph" below is very information-rich. The curved lines in the center show all of the interactions between characters, with intensity shown by the gray-to-black coloring ; thus in the snapshot to the right Juliet and Nurse have many more conversations (betweeen themselves and across to Romeo) than either Chorus or Abraham. Some of the datasets are unweighted and so all gray. Weighting makes an enormous positive difference in the grouping, so when it's available in the data I don't offer an unweighted analysis option.
The "ring graph" below is very information-rich. The curved lines in the center show all of the interactions between characters, with intensity shown by the gray-to-black coloring ; thus in the snapshot to the right Juliet and Nurse have many more conversations (betweeen themselves and across to Romeo) than either Chorus or Abraham. Some of the datasets are unweighted and so all gray. Weighting makes an enormous positive difference in the grouping, so when it's available in the data I don't offer an unweighted analysis option.